





Der Visual Compiler Compiler, kurz VCC, ist ein grafisch ansprechendes Werkzeug zur Erstellung von Scannern und Parsern für die Zielsprachen Scheme und C#.
Zunächst gibt es verschiedene Symbole in der Symbol-Leiste, welche Ihnen jederzeit zur Verfügung stehen.
| Öffnen | Öffnet ein vorhandenes Projekt im Format .xml |
| Speichern | Speichert das geöffnete Projekt am gewünschten Ort. |
| Rückgängig | Macht den letzten Bearbeitungsschritt rückgängig. |
| Wiederholen | Stellt den letzten rückgängig gemachten Schritt wieder her. |
| Compiler generieren | Erzeugt einen Compiler aus Scanner und Parser in der gewünschten Zielsprache (C# oder Scheme). |
| Export Automat | Erzeugt einen Automat aus dem Parser und öffnet diesen mit AutoEdit. |
| Export T-Diagramm | Erzeugt diesen Compiler als Baustein für TDiag. |
Wenn Sie einen neuen Compiler erstellen wollen, müssen Sie "Neue VCC-Datei" anwählen und unter "Sprachtyp" Ihre Zielsprache wählen. Zur Zeit stehen Scheme und C# zur Auswahl (Abb.13). Die Zielsprache bedeutet hier die Sprache, in welcher der Compiler geschrieben wird.
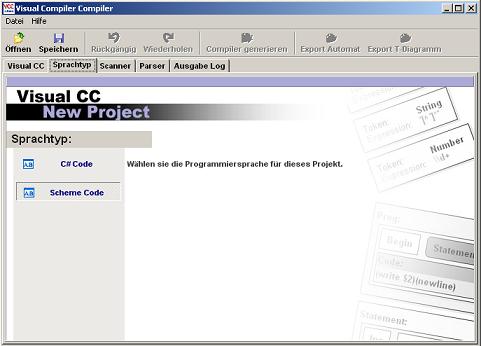
Abb. 13: Auswahl der Zielsprache
Ein Scanner dient dazu, einen Zeichenstrom in Token zu klassifizieren, um ihn für den Parser brauchbar zu machen. Der Zeichenstrom wird immer von links nach rechts eingelesen. Einer Tokenklasse müssen bestimmte Zeichen oder Zeichenfolgen zugeordnet sein. Weil es vorkommen kann, dass eine Zeichenfolge, die einer bestimmten Tokenklasse zugeordnet werden kann, Zeichen oder Zeichenfolgen enthält, die zu einer anderen Tokenklasse gehören, wird immer das längere Token gewählt. Um Tokenklassen zu erstellen, können Sie das entweder im Menü auswählen (Rechtsklick auf Arbeitsfläche) oder die dafür vorgesehene Schaltfläche benutzen. Hier eine Liste der Schaltflächen:
 | Tokenliste anzeigen | Blendet links oben neben der Arbeitsfläche eine Übersicht der Tokenklassen ein. |
 | Tokeneigenschaften anzeigen | Blendet links unten neben der Arbeitsfläche ein Fenster für die Tokeneigenschaften ein. |
 | Token nach unten bewegen | Verschiebt eine Tokenklasse in der Übersicht nach unten. |
 | Token nach oben bewegen | Verschiebt eine Tokenklasse in der Übersicht nach oben. |
 | Neues Token erstellen | Erstellt eine neue Tokenklasse. |
 | Gewähltes Token löschen | Löscht eine Tokenklasse. |
Eine Tokenklasse kann alternativ mit dem Menü (Rechtsklick) gelöscht werden. Zu den Eigenschaften einer Tokenklasse gehören Name, Inhalt und Farbe. Letztere hat natürlich nur für Ihr Layout Bedeutung. Die Namen der Tokenklassen werden in der Übersicht angezeigt. Auf Sonderzeichen und Umlaute sollte hierbei verzichtet werden. Leerzeichen sind nicht erlaubt. Der Name IGNORE ist vorbelegt und kann ebenfalls nicht mehr verwendet werden. Beachten Sie die Reihenfolge der Token! Sollte der Scanner zum Beispiel Schlüsselwörter von gleichnamigen Strings unterscheiden, sollte das Schlüsselwort-Token eine höhere Priorität haben und somit weiter oben stehen. Die Inhalte der Tokenklassen können auch mit regulären Ausdrücken beschrieben werden (s. Abb.14). Um ASCCI-Zeichen von Zeichen mit besonderer Bedeutung zu unterschieden kann die Bedeutung der Zeichen mit einem vorangestellten "\" außer Kraft gesetzt werden, z.B. bei *, +, [, ]...
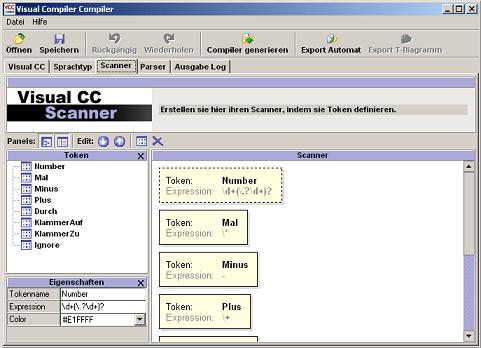
Abb. 14: Beschreibung von Tokenklassen
Ein Parser nimmt den vom Scanner gelieferten Tokenstrom und prüft, ob daraus ein gültiger Syntaxbaum entsteht. Dazu wendet er bestimmte grammatische Regeln an. Um eine neue Regel zu erstellen, können Sie diesen Menüpunkt per Rechtsklick auswählen oder wieder aus den Schaltflächen wählen:
| Parser-Baumansicht anzeigen | Blendet links oben neben der Arbeitsfläche eine Baumansicht der Regeln ein. |
| Eigenschaften anzeigen | Blendet links unten neben der Arbeitsfläche ein Fenster für die Eigenschaften der gewählten Regel oder des gewählten Tokens ein. |
| Element nach unten bewegen | Verschiebt eine ganze Regel, eine einzelne rechte Regelseite oder ein Einzelelement nach hinten, je nachdem, was markiert ist. |
| Element nach oben bewegen | Verschiebt eine ganze Regel, eine einzelne rechte Regelseite oder ein Einzelelement nach vorne, je nachdem, was markiert ist. |
 | Neue Regel erstellen | Erstellt eine neue Regel. |
 | Rechte Regelseite hinzufügen | Erstellt eine neue rechte Regelseite. Das entspricht in der Grammatik dem "|" |
 | Regel zur rechten Regelseite hinzufügen | Fügt eine Regel in eine rechte Regelseite ein. Weil nur vorhandene Regeln zur Auswahl stehen, gibt es hier eine Auswahlliste. |
| Token zur rechten Regelseite hinzufügen | Fügt ein Token in eine rechte Regelseite ein. Weil nur vorhandene Token zur Auswahl stehen (s. Scanner), gibt es auch hier eine Auswahlliste. |
| selektiertes Element löschen | Löscht ein Element. |
Eine Regel besteht aus einer oder mehrerer rechter Regelseiten (kontextfreie Grammatik), die selbst aus allen möglichen Regeln oder Token bestehen können. Die Token liefert Ihnen der Scanner, die Regeln bestimmen Sie hier. Jede von Ihnen erstellte Regel muss definiert werden! Die vom Scanner gelieferten Token entsprechen den Terminalen. Diese kommen in beliebigen, von Ihnen festgelegten Regeln vor. Eine Regel darf sich auch selbst enthalten (Rekursivität). Da für die Programmierung kontextfreie Grammatiken genutzt werden, steht auf der linken Regelseite stets nur ein Nichtterminal. Dieses entspricht dem Namen der Box, in der diese Regel definiert wird. Selbstverständlich darf auch Epsilon auf der rechten Seite stehen. Das wird einfach durch eine leere graue Box in der Regel-Box dargestellt (s. Abb. 15).
Die folgenden Abbildungen zeigen beispielhaft die rekursive Regel "Input", die Epsilon verwendet. Eine solche Regel hat zwei Regeln auf der rechten Regelseite, wie die Abbildungen zeigen.
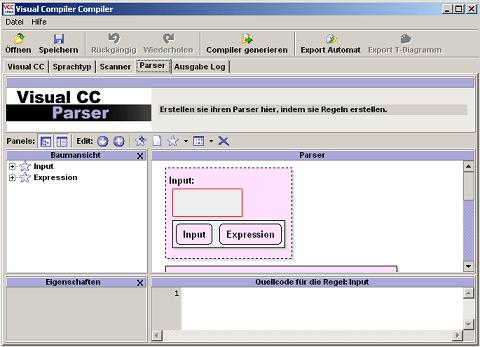 | 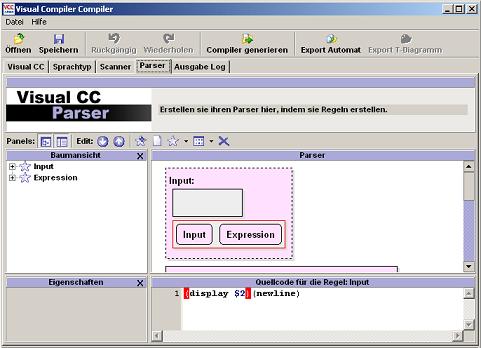 |
| Abb. 15: Beschreibung einer Epsilon-Regel | Abb. 16: Beschreibung einer rekursiven Regel |
Beispiel: Um die Regel A -> Bx | y (A und B sind Nichtterminale, x und y sind Terminale) zu erstellen müssen Sie nacheinander...
Der Quelltext des Compilers wird in der anfangs ausgewählten Zielsprache des Compilers erstellt, also entweder mit C#-Code oder mit Scheme-Code. Die Syntax entspricht also der jeweiligen Sprache. Jede Regel entspricht einer Funktion. Während die Epsilon-Regel keinen Quellcode benötigt, greifen die anderen Regeln auf die Variablen $$ und $1 ... bis $n zurück. $$ ist die Rückgabe der Funktion, und die Variablen $1, $2.... Stellen die einzelnen Regeln und Token dar.
Beispiel:
| Regel1 => Regel2 Token1 Regel3 wäre enthalten in den Variablen |
| $$ = $1 $2 $3 |
| da das zweite Element ein Token ist heißt das soviel wie: |
| $$ = $1 + $3 , wenn Token1 ein "+" ist. |
Auf diese Art kann man in der Funktionsdefinition auf die Funktionselemente zugreifen und Werte zurückgeben. Man beachte, dass Ausgabefunktionen wie print immer erst etwas ausgeben, sobald die zugehörige Variable terminiert, aber auch, dass eine von print erzeugte Ausgabe zu einem Rückgabewert werden kann. Solche Definitionen führen oft zu unerwünschten Effekten. Daher ist es ratsam, solche oder ähnliche Funktionen nur in der Spitzenfunktion (Spitzensymbol) zu verwenden (s. Abb. 16)! Es ist außerdem möglich, wenn keine Regel ausgewählt ist, globale Definitionen zu erstellen. Mit deren Hilfe kann man Hilfsfunktionen oder globale Variablen erstellen, falls dies erwünscht ist.
In Abb. 16 steht als Beispiel der Quellcode (hier
Scheme-Code) (display $2)(newline) für die Regel Input => Input
Expression. In $2 steht der Inhalt von Expression, welcher hier also auf dem
Bildschirm mit Zeilenumbruch ausgegeben wird. Da Input hier das
Spitzensymbol ist, ist das ohne weiteres möglich.
Auf den folgenden zwei Abbildungen sind zwei Parserbäume zu sehen, beide beziehen sich auf das gleiche Eingabewort und eine äquivalente Grammatik. Der Unterschied zwischen den Grammatiken ist nur, dass die linke eine LL-Grammatik ist und die andere eine LR-Grammatik. Das Ergebnis muss in beiden Fällen immer gleich sein. In diesem Beispiel ist das auch so, allerdings sieht man, dass die durchgereichten Zwischenergebnisse sich voneinander durchaus unterscheiden können. Was sind also die Konsequenzen beim Parserbau mit VCC? Weil YACC rechtsrekursiv arbeitet, müssen Sie auch Ihre Grammatik in dieser Form halten. Dabei gilt während des Parsings, dass eine angewendete Regelseite bei LALR-Parsern zuerst rechts ersetzt wird. Aus diesem Grund müssen auch in der Grammatik die rekursiven Ausdrücke immer links stehen, damit diese zuletzt ersetzt werden.
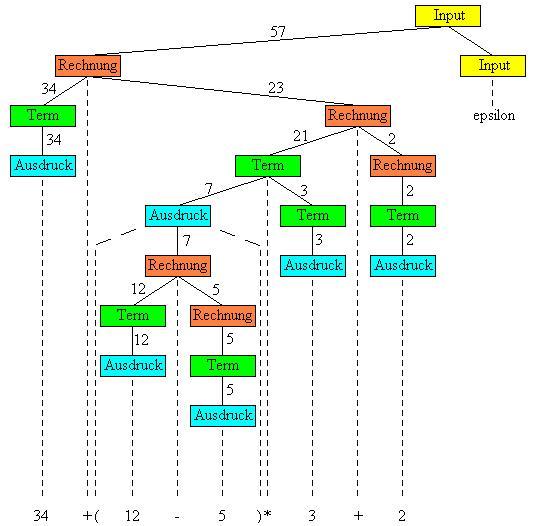 | 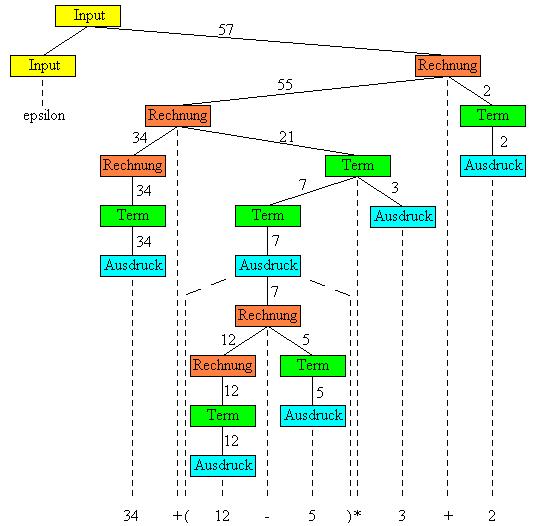 |
| Parserbaum einer linksrekursiven Grammatik | Parserbaum einer rechtsrekursiven Grammatik |
Wenn der Compiler nun fertig ist, können Sie ihn, je nach Zielsprache, als .cs oder .ss speichern und ausführen. Haben Sie Scheme als Zielsprache gewählt, so öffnet sich der SchemeEdit. Desweiteren können Sie nun in der letzten Registerkarte "Ausgabe Log" die Zustände des entstandenden Kellerautomaten sehen, welcher durch die kontextfreie Grammatik entsteht. Sollte es dabei zu Problemen kommen, z.B. durch falsche Tokenbenennung, so werden diese Fehler an dieser Stelle aufgedeckt. Weiter unten sehen Sie die Ausgabe, die bei der Compilerkonstruktion von YACC erzeugt werden. Häufig kommt es hier zu Fehlern wie z.B. "shift/reduce problem". In diesem Fall sollten Sie Ihre Grammatik auf Mehrdeutigkeiten prüfen! Der Parser kann hier zwar seine Arbeit verrichten, es könnten aber ungewollte Ergebnisse bei der Übersetzung auftreten. Im Idealfall meldet YACC einen fehlerfreien Ablauf.
Wir wünschen Ihnen viel Spaß bei der Verwendung von VCC!